使用pyroscope+ holmes 加速找到服务瓶颈
背景及痛点分析
在软件开发过程中,我们会根据需求快速迭代项目,但随着功能的增加,系统效率可能会出现瓶颈。
至今,我们已经采用了日志链路追踪和Sentry警告等解决方案来辅助问题排查。然而,在所有已知方案都无法提供解决思路的情况下,我们需要迅速地垂直拓展。这通常意味着直接拉取线上的pprof进行分析。而且,我们可能会面临需要提高CPU和内存的压力(就如同做面食,面多了加水,水多了加面)。然而,这只是暂时的解决办法,不能从根本上解决问题。因此,我建议大家在使用pprof在线服务时,要关注服务性能问题。
如果你希望持久化这些数据,我们可以使用Pyroscope。这个工具能够快速定位到哪些地方的执行速度较慢,哪些地方的性能消耗较大。Pyroscope支持多种语言,包括Go,
Python, Java, Ruby, Rust, PHP等。如果你希望在本地快速找出性能瓶颈,请继续阅读本文。
先上图,看效果
上线一段时间后监控cpu告警,可以看到最近12小时内,凌晨2点告警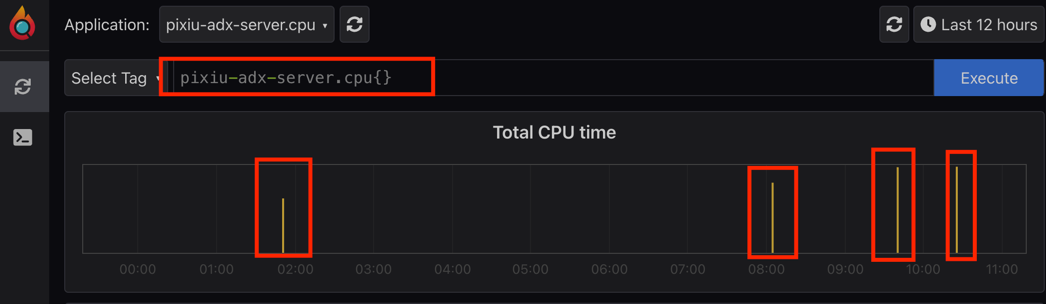
选择一个告警看下具体分析,通过火焰图我们可以看到最宽的表示当前时间节点消耗cpu做多的函数是 FlowAdv() :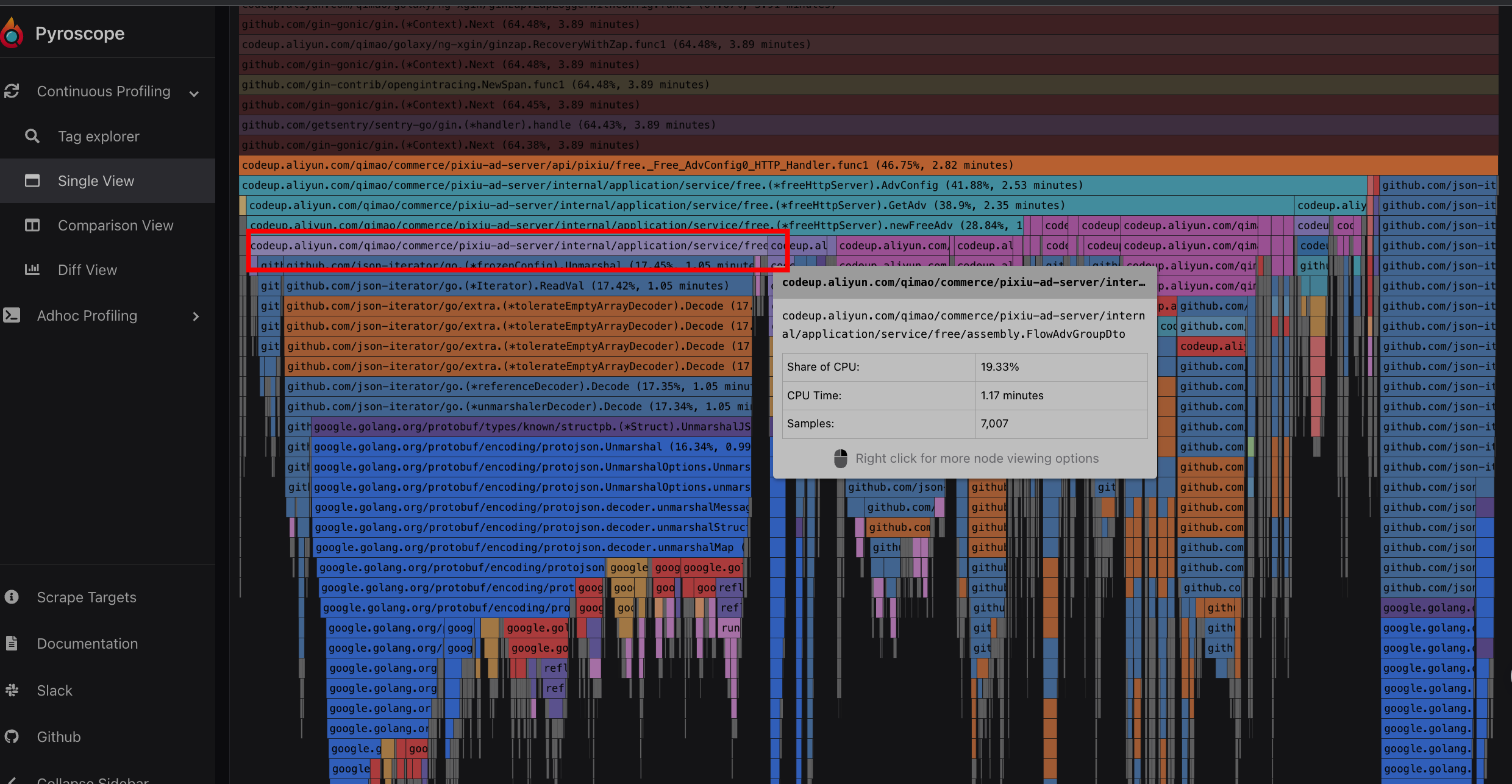
在项目中搜索该函数后,定位到代码: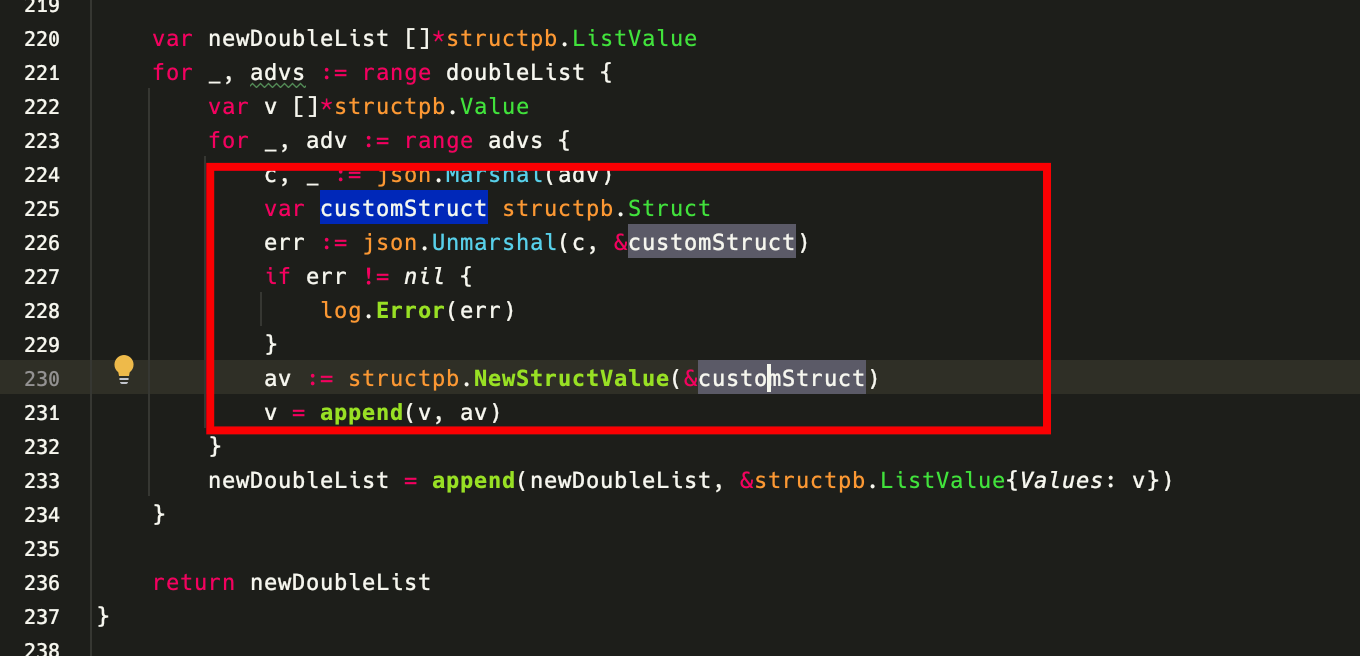
代码分析:
对代码的深入分析揭示了一些特性:在for循环中,我们采用了序列化函数,把业务结构体转换为字节流,再反序列化给pb结构体。在这个过程中,我们使用了谷歌的 google.protobuf.Struct 结构。这种选择源于目标结构类型的不确定性,所以我们采用了动态类型结构进行接收。但由于这样做会导致序列化过程的性能消耗较大,因此,我们需要考虑使用固定类型的结构体,以此避免反序列化带来的性能损耗。
使用接入流程
经过以上分析,我们可以看到,即便是程序中的微小性能问题也能被有效捕捉,从而最大程度地降低了大家对pprof的陌生感。接下来,让我们详细介绍其使用流程:
- 首先,我们要接入pyroscope SDK,这是为了格式化展示pprof。
- 在程序中接入 holmes,用于上报关键指标。
- 配置程序中的上报地址,并启动程序。
- 与运维团队联系,寻求他们在集群中部署pyroscope监控,同时提供pyroscope平台的地址。
- 在pyroscope平台上查看并分析结果。
- 根据结果优化代码,并根据pod的状态重新上线。
程序中开启pyroscope监控
- 在业务程序中拉取 pyroscope 包依赖
go get github.com/pyroscope-io/client/pyroscopefunc main() {
pyroscope.Start(pyroscope.Config{
ApplicationName: "qm-app",
ServerAddress: serverAddress,
Logger: pyroscope.StandardLogger,
Tags: map[string]string{"region": os.Getenv("REGION")},
})
run()
}Holmes接入,发现业务性能问题,和上报机制
package main
func InitHolmes() {
cfg := pyroscope_reporter.RemoteConfig{
// 上报地址
UpstreamAddress: pyroscopeConf.Endpoint,
// 上报请求超时
UpstreamRequestTimeout: 3 * time.Second,
}
// 要填自己pod的hostname 这样作为tag好排查
tags := map[string]string{"region": os.Hostname}
pReporter, err := pyroscope_reporter.NewPyroscopeReporter(pyroscopeConf.Application, tags, cfg, holmes.NewStdLogger())
if err != nil {
fmt.Printf("NewPyroscopeReporter error %v\n", err)
return
}
h, err = holmes.New(
holmes.WithProfileReporter(pReporter),
holmes.WithDumpPath("/tmp"),
holmes.WithMemoryLimit(100*1024*1024), // 100MB
holmes.WithCPUCore(2), // 双核
holmes.WithCPUDump(20, 100, 150, time.Minute*2),
holmes.WithMemDump(50, 100, 800, time.Minute),
holmes.WithGoroutineDump(200, 100, 5000, 200*5000, 1*time.Minute),
holmes.WithCollectInterval("1s"),
)
h.EnableCPUDump().
EnableGoroutineDump().
EnableMemDump().
Start()
}
展开介绍下holmes中每个配置的用意
- holmes.WithMemoryLimit(100 * 1024 * 1024):
- 内存率配置,当计算内存指标时,默认系统中mem单位是byte所以这里做个单位置换,这个参数用于分母,X字节/配置比率,我们这里默认用100Mb作为单位,每个100Mb是1%
- holmes.WithCPUCore(2):
- cpu率配置,本地mac一般都是8核或者16核,看cpu使用率时候不准确,
默认常用k8s中分配pod都是双核的,所以这里设置为2,这样采集cpu信息比较及时准确,当计算CPU指标时,这个参数用于分母,X核/配置核数,这样方便后面配置的计算,系统默认使用最大核数
runtime.GOMAXPROCS(-1)。
- cpu率配置,本地mac一般都是8核或者16核,看cpu使用率时候不准确,
- holmes.WithCPUDump(20, 100, 150, time.Minute * 2):
- CPU 核每次增长大于最近10次统计平均的2倍 的时候,打印内存栈信息, 当前绝对值>150 时候,上报CPU信息
- holmes.WithMemDump(50, 100, 800, time.Minute):
- 最近10次统计平均的2倍 小于当前的,打印内存栈信息 小于50Mb不上报,
- holmes.WithGoroutineDump(200, 100, 5000, 200 * 5000, 1 * time.Minute):
- 当goroutine指标满足以下条件时,将会触发上报操作。 current_goroutine_num > 200 && current_goroutine_num < 200 *
5000 &&
current_goroutine_num > 200% * 前10次统计协程数的平均值 || current_goroutine_num > 5000.
- 当goroutine指标满足以下条件时,将会触发上报操作。 current_goroutine_num > 200 && current_goroutine_num < 200 *
- holmes.WithCollectInterval(“1s”):
- 默认逻辑5s频率主动收集统计,所以设置间隙小一点。这里每秒统计目的是保证上报及时性,若大于1min,可能在期间发生故障oom,而不上报,导致错过上报机会。
注意:各个业务程序的配置需要根据自身pod(服务器资源)配置情况,进行调整,以保证采集的指标数据准确性。这里展现的配置是 2c3g
pod为例
集群部署安装过程
添加 Pyroscope Helm 存储库
在本地拉取安装 Pyroscope镜像
helm repo add pyroscope-io https://pyroscope-io.github.io/helm-chart注: 如果本地没有安装helm管理工具,可以先行执行 :brew install helm
安装到指定阿里云/华为云集群,并指定命名空间 test 「先确认自己是否有集群部署权限」
helm --kubeconfig ~/.kube/config install pyroscope pyroscope-io/pyroscope -n test验证下是否安装成功
kubectl --kubeconfig ~/.kube/config get pods -n test ===== NAME READY STATUS RESTARTS AGE pyroscope-7975454b55-24dnm 1/1 Running 0 9m30s
思考:为什么要使用临时分析
Pyroscope 最近推出了 profiling 性能分析功能,那么为什么官方要推出这个功能呢?原来,Pyroscope推出这个开源平台是为了让开发者能够在平台上线后,快速定位到效率瓶颈。而且,我们每天都有大量的pprof报告上传到展示服务性能的平台上,但时间久了,人们可能会感到疲劳,或者对其失去感知。因此,我们采用了holmes进行关键指标的上报,这意味着所有上报的内容都是有价值的。如此一来,我们就能快速定位问题,而无需盲目寻找。
使用界面
打开浏览器,输入http://localhost:4040,就可以看到如下:
点开 CPU Profiling 可以看到如下: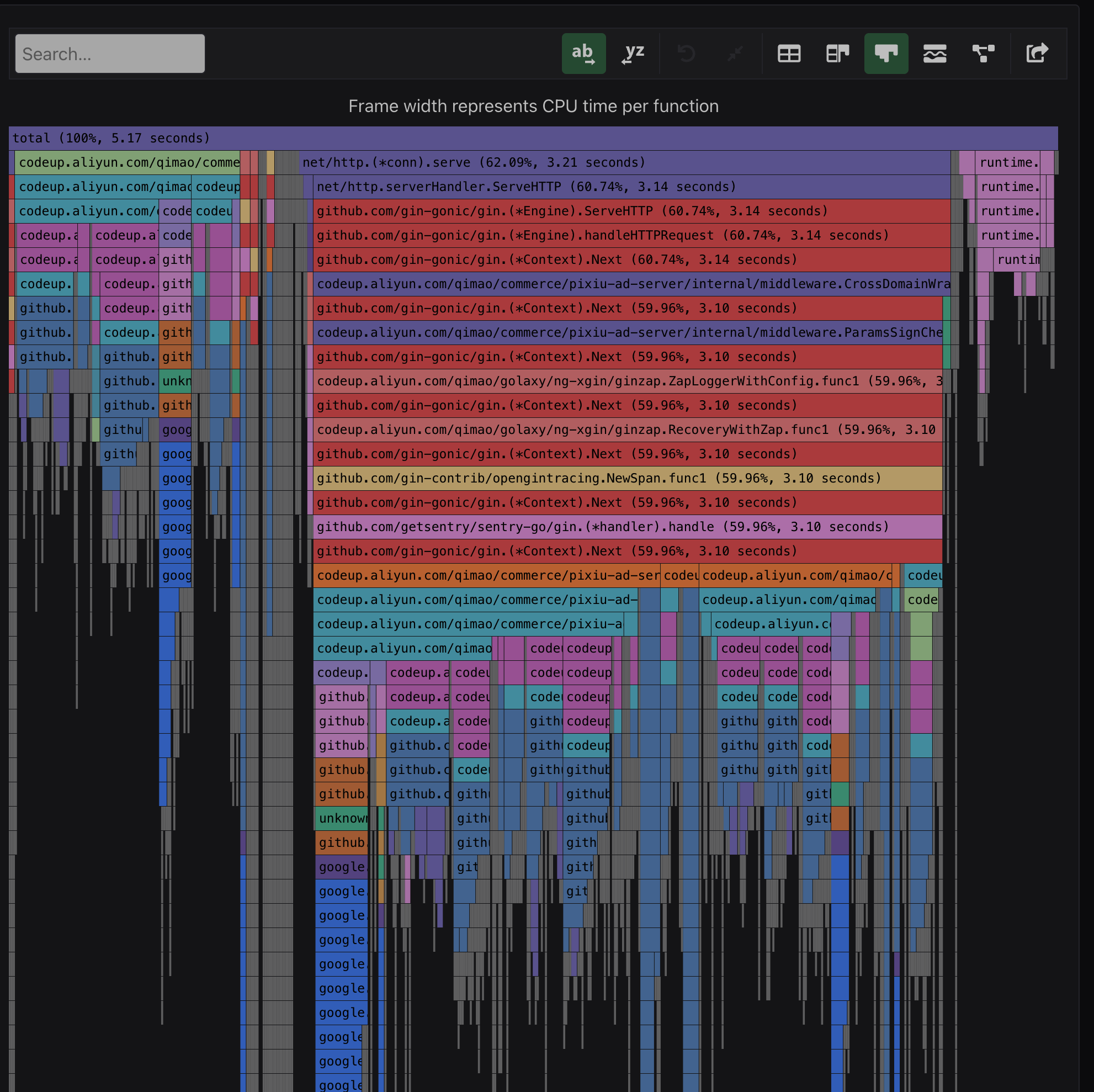
从上图可以看到点选左边的Single View,就可以看到上面出现pyroscope data的Tab,里面就是该目录里面的所有数据,可以立即显示及比较数据。
心得总结
这个功能极大地助力了我们的工作,特别是当我们想在本地环境进行一些性能分析时。尽管我们可以使用pprof,但缺乏一个友好的用户界面使得识别并定位错误变得困难。然而,现在我们可以将数据分享给其他同事,一起协作解决问题。一旦服务按照常规模式上线,我们不会启用pyroscope实时功能,以保证服务接收到的数据是有效的且无干扰,并结合Prometheus和Grafana寻找在特定时间点的性能瓶颈。
感谢
pyroscope从2022年11月开源后,各个厂商都在使用,也有很多人在使用,这里感谢商业化研发组小伙伴,以及
子龙,忠祥(运维伙伴)的大力帮助,才有了现在这样的效果,也希望大家多多支持,多多使用,多多反馈,让我们对生产问题不在畏惧。